This chapter applies the structural estimator to a candidate-choice conjoint whose design follows Graham and Svolik (2020). Respondents choose between pairs of hypothetical U.S. candidates; one attribute captures the candidate’s willingness to engage in undemocratic behavior (ignoring a court ruling, restricting the opposition press, or banning an opposition rally). The original study asks how much voters penalize co-partisan candidates for violating democratic norms, and whether strong partisanship leads to tolerance of such violations.
The structural model adds value here because it decomposes the population-average penalty for undemocratic behavior into direction and intensity, and traces the heterogeneity back to respondent-level partisanship — without re-estimating on subsets.
4.1 Data preparation
Load the Graham-Svolik subset and inspect its structure. Each respondent contributes about 13 forced-choice tasks against pairs of hypothetical candidates.
Each respondent sees up to 13 matchups with two candidate profiles each. The respondent-level moderators include ideology (resp_ideo, 1–7), party identification (resp_pid, -3 to 3), Trump approval (resp_trump, 1–4), demographics (age, gender, race, education, income), and dispositional measures (authoritarianism, political knowledge) — 12 moderators in total. This is a reduced set relative to the paper (see the overview), so the numbers below are illustrative.
The dem_code attribute has 16 levels in three families: good-governance (g_*, 7 levels), undemocratic actions (u_*, 7 levels), and valence violations (v_*, 2 levels). The raw choice rates make the families crystal clear:
agg <-aggregate(choice ~ dem_code, data = gs2020, FUN = mean)agg[order(-agg$choice), ]
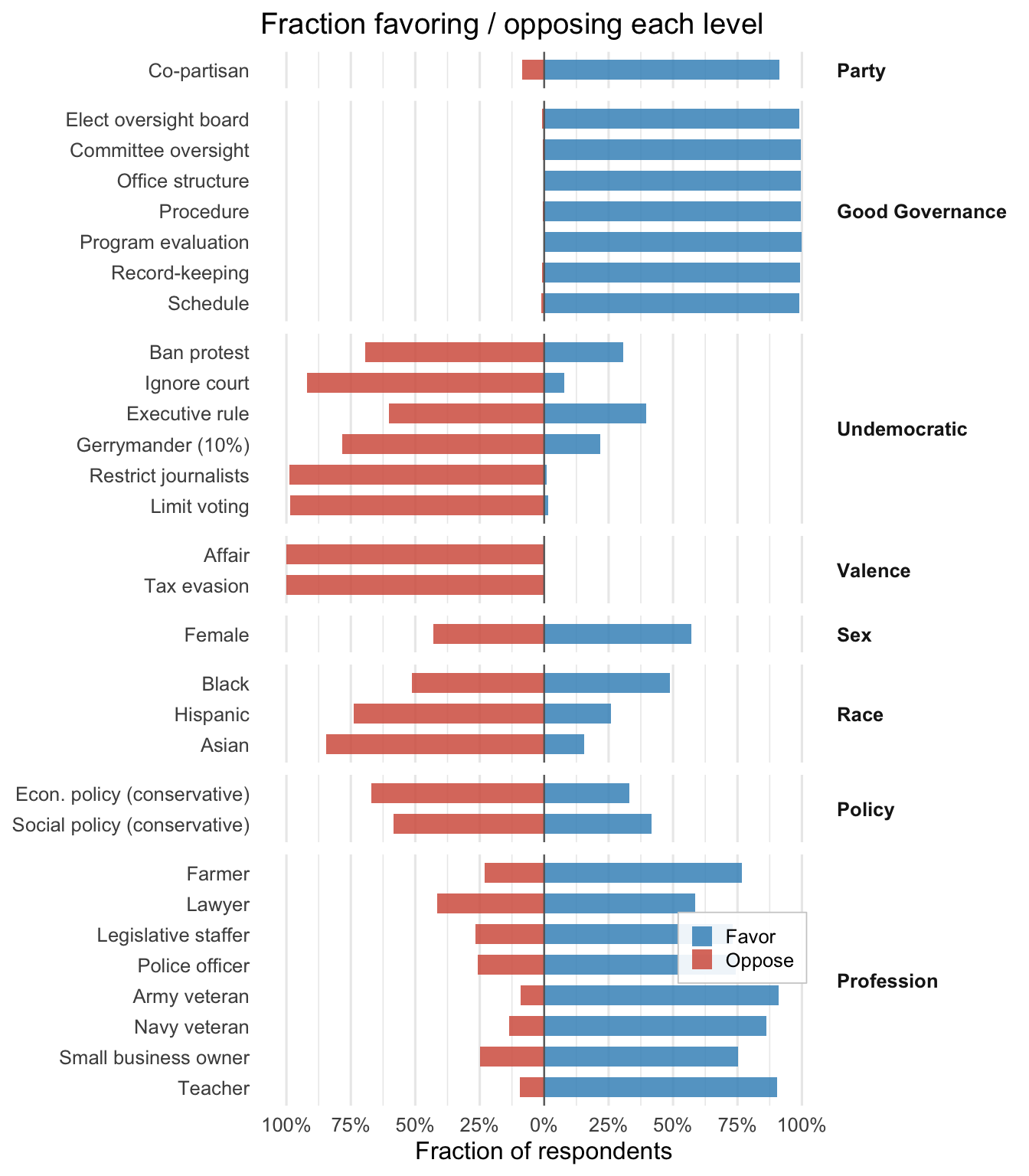
Every g_* item is chosen at rate \(> 0.55\); every u_* item at rate \(< 0.42\); every v_* item at rate \(< 0.35\). The labels are correct. But the default factor reference is g_boardElect (alphabetically first), so when we fit the model with default contrasts, the g_* coefficients are estimated relative to another good-governance item, which makes the within-g_ comparisons noisy and a few of them slightly negative.
To get a more interpretable plot that lines up with the paper’s “voters favor good governance” finding, we re-level dem_code so that the reference is the mildest undemocratic action, u_gerry2 (slight gerrymandering). With this baseline, every g_* item shows a clearly positive coefficient (good-governance preferred over mild undemocratic behavior), other u_* items are near-zero or negative (worse than mild gerry), and v_* valence items are strongly negative.
gs2020$dem_code <- stats::relevel(factor(gs2020$dem_code),ref ="u_gerry2")levels(gs2020$dem_code)[1] # confirm new reference
The summary above reports Stage 2: map_c5 — the empirical-Bayes MAP refinement of paper §3. The DML co-partisan coefficient (a large, precisely-estimated positive effect in the paper) is computed from the Stage-1 DNN only; the refined respondent-level betas (used by the distributional and structural quantities below) sit on fit_gs$beta_hat. Pass stage2 = "none" to recover v0.1 behavior.
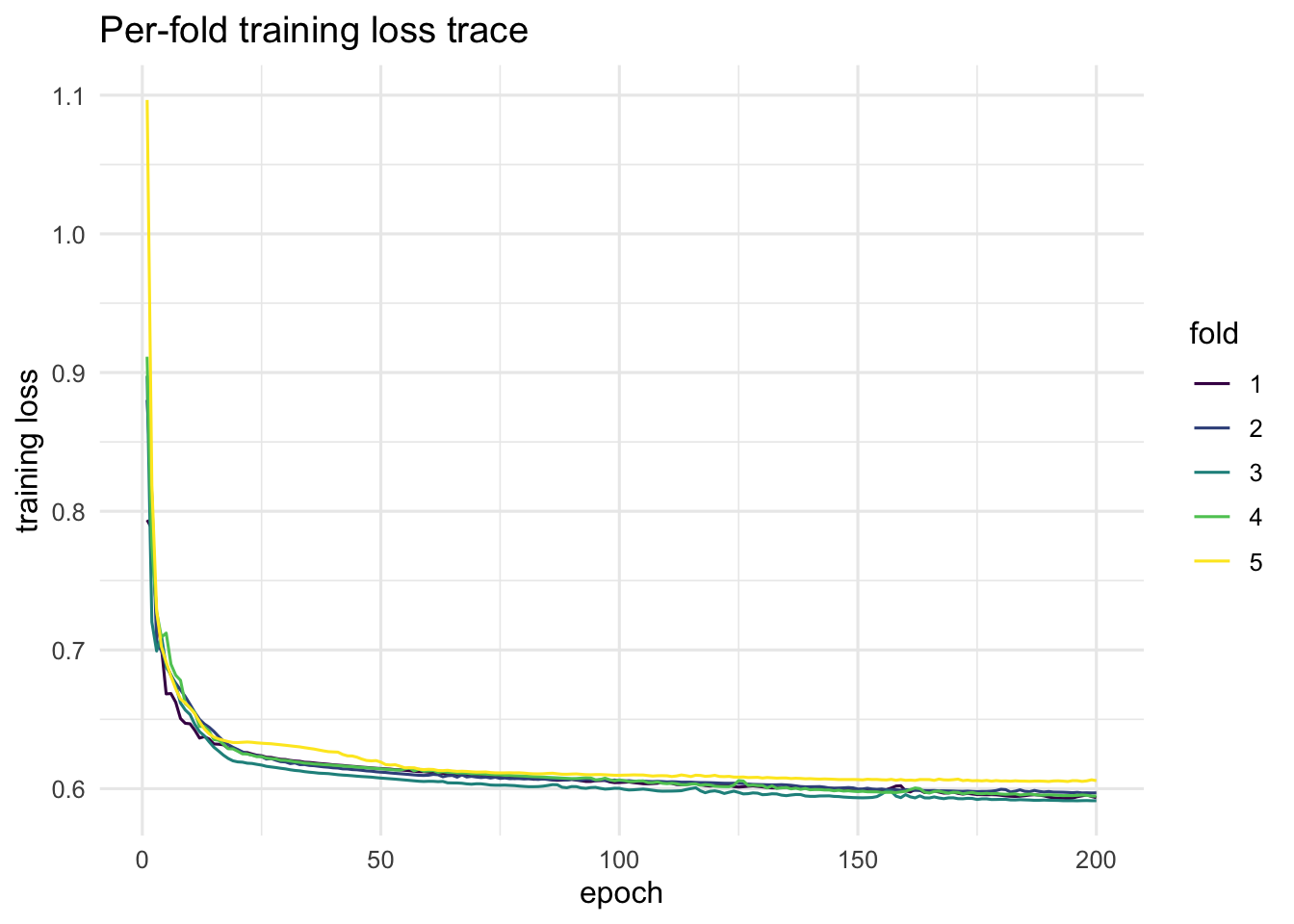
plot(fit_gs, "loss_trace")
4.3 Population-average estimates
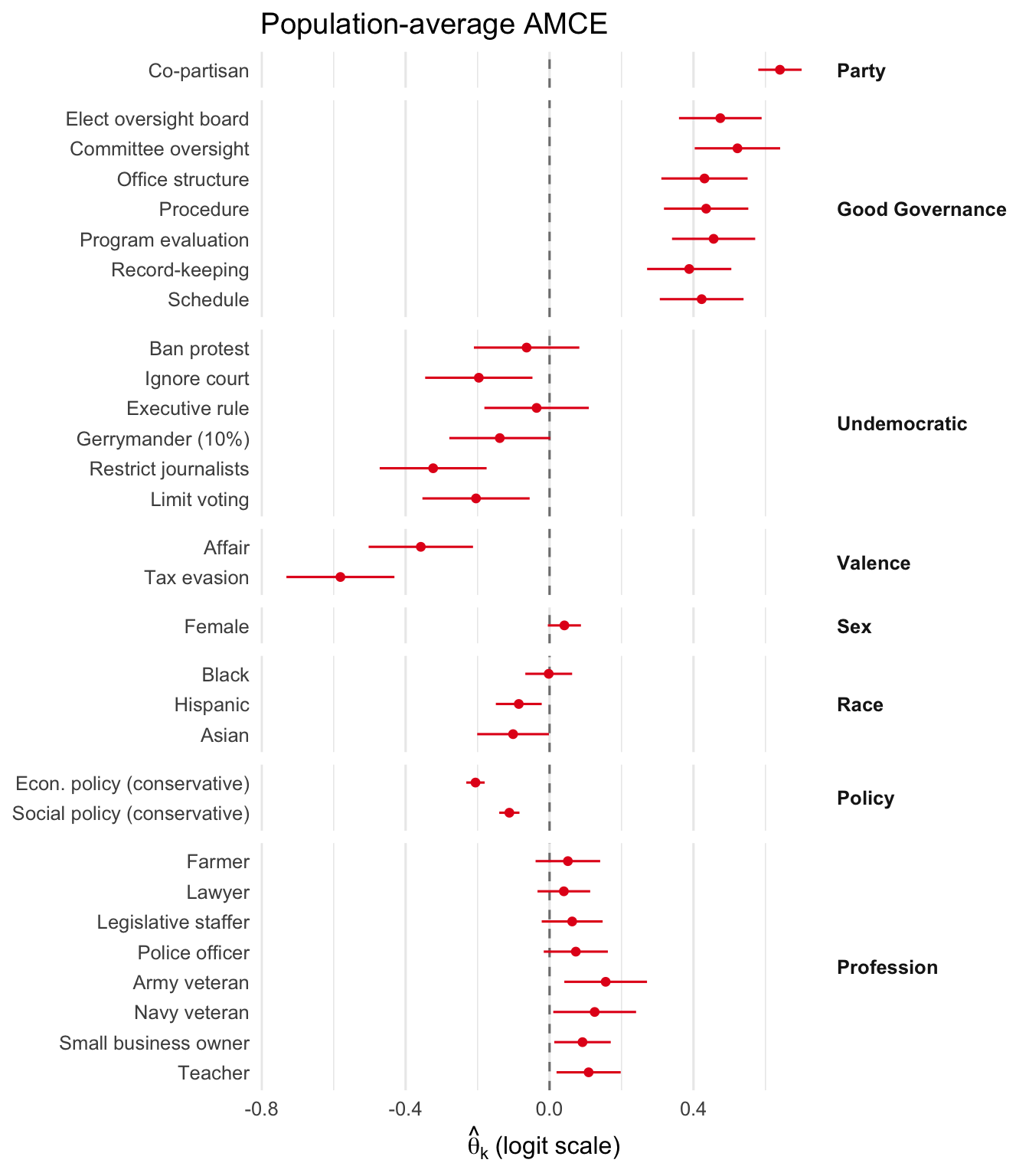
NoteHow to read the AMCE plot
We re-leveled dem_code above so that the reference is u_gerry2 (mild undemocratic action). All dem_code coefficients are now read relative to that baseline:
Other u_* (undemocratic) items: near zero or negative — similar to or worse than mild gerry.
v_* (valence violation) items: strongly negative — voters reject sex affairs / tax evasion even relative to mild undemocratic behavior.
This is the paper’s directional finding: voters favor good governance and oppose democratic backsliding.
Plot the population-average coefficients (DML on the logit scale).
plot_amce(fit_gs, groups = gs_groups, labels = gs_labels)
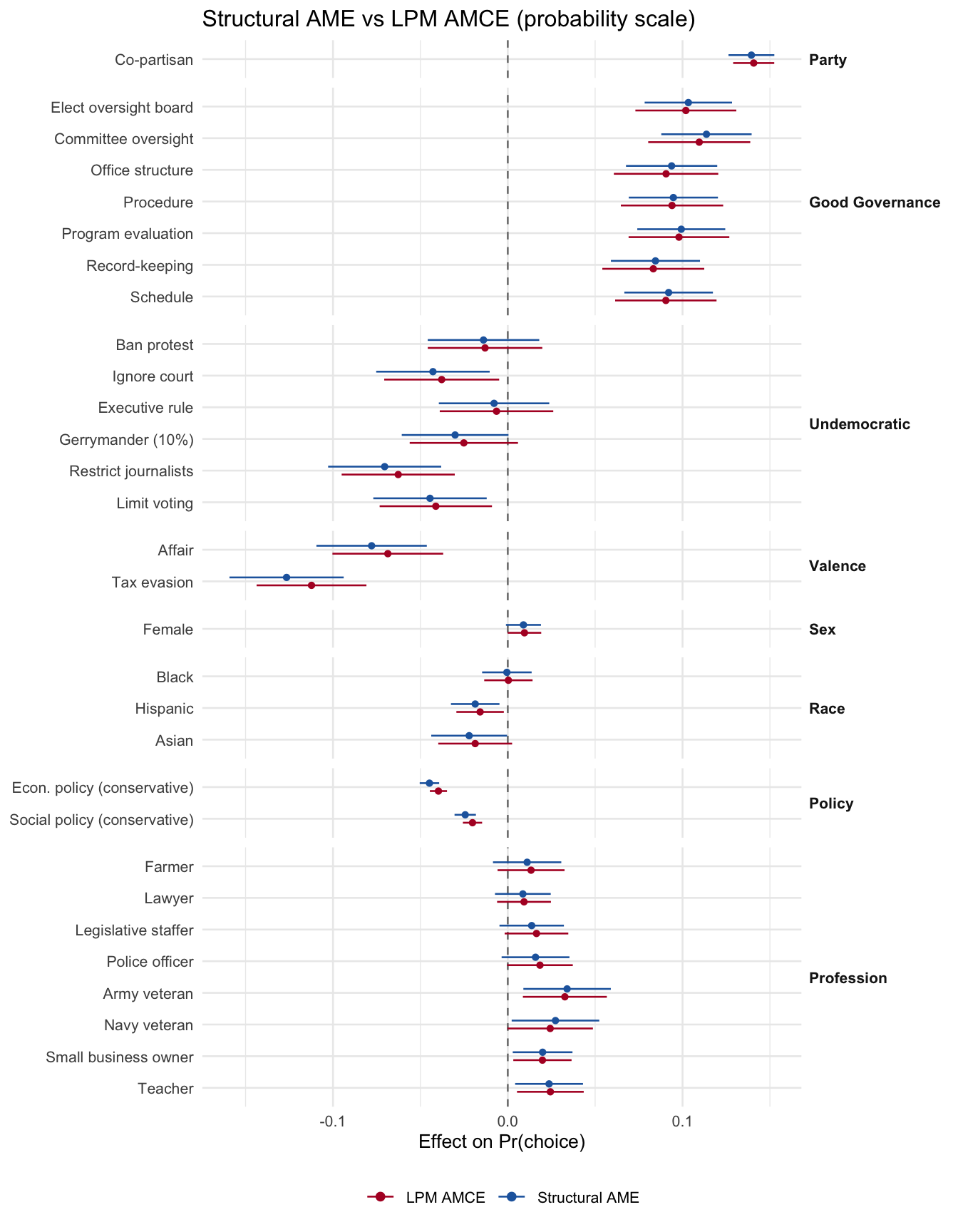
4.3.1 Structural AME vs reduced-form AMCE
Overlay the structural model’s average marginal effects (probability scale) against the linear-probability-model AMCE. Under correct specification the two coincide.
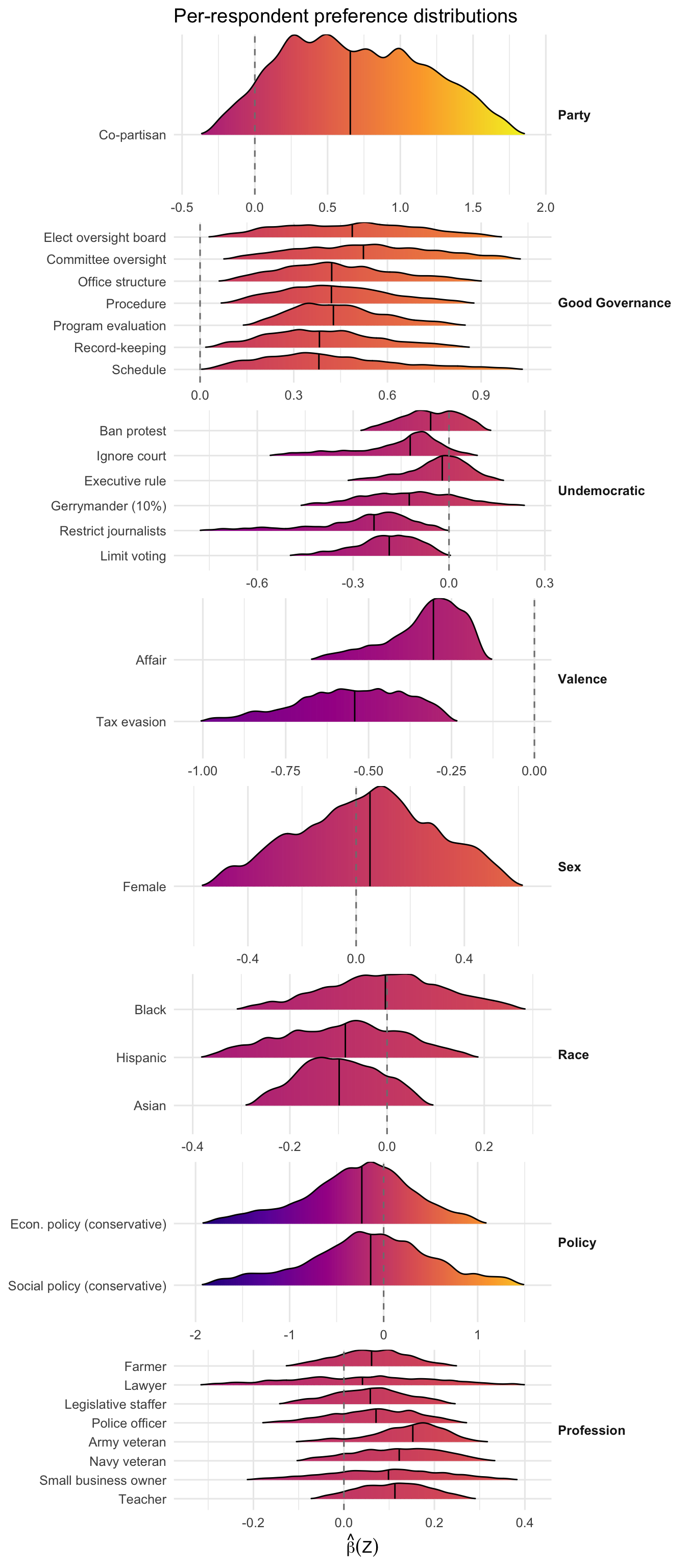
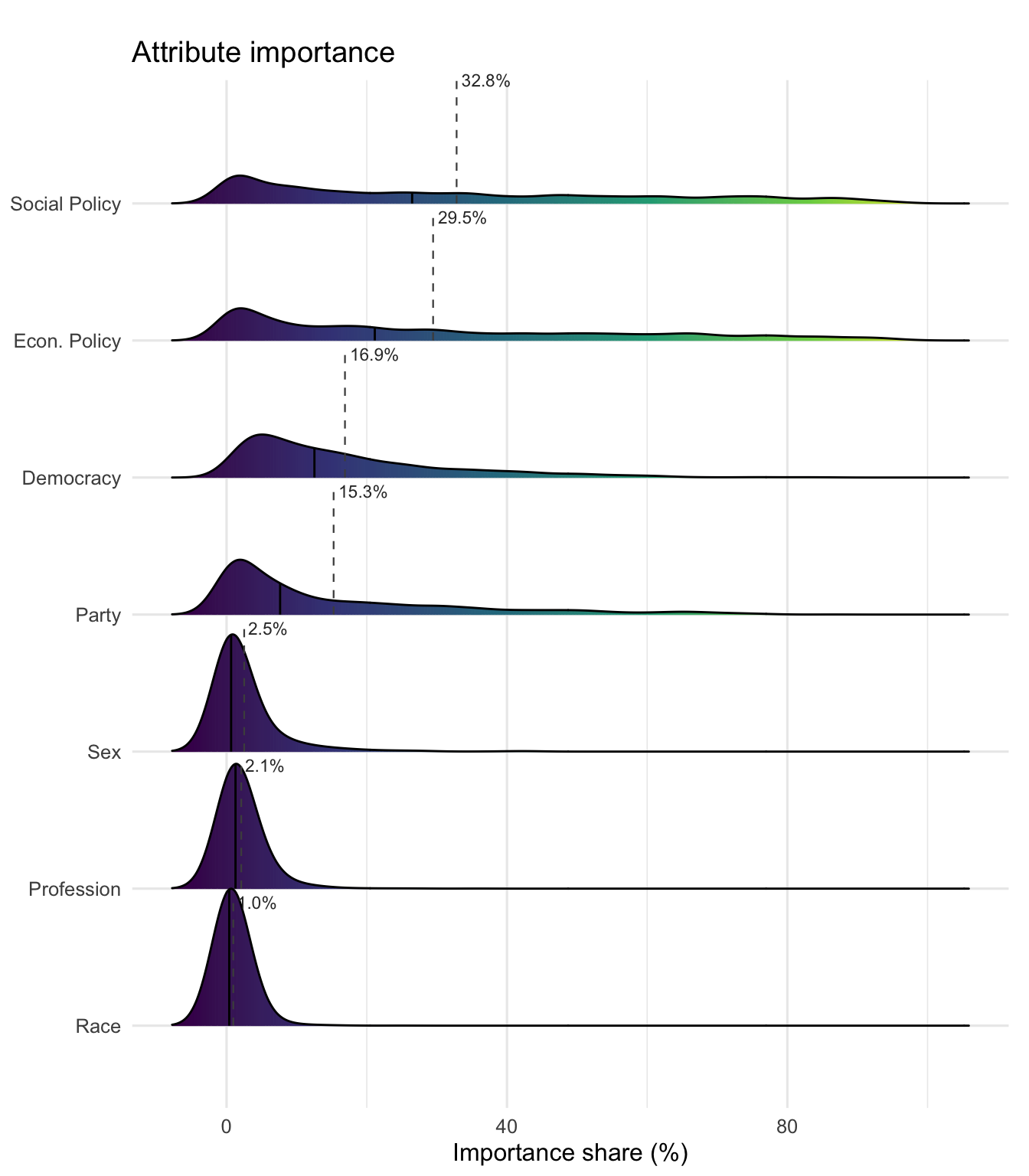
Ridgeline densities show how each per-respondent coefficient \(\hat\beta_k(\mathbf Z_i)\) is distributed across the sample. Undemocratic-action densities should sit entirely left of zero; good-governance densities sit near zero (relative to the g_boardElect reference, see the callout above).
plot(fit_gs, "beta_ridgelines", groups = gs_groups, labels = gs_labels)
4.5 Structural quantities
4.5.1 Attribute importance
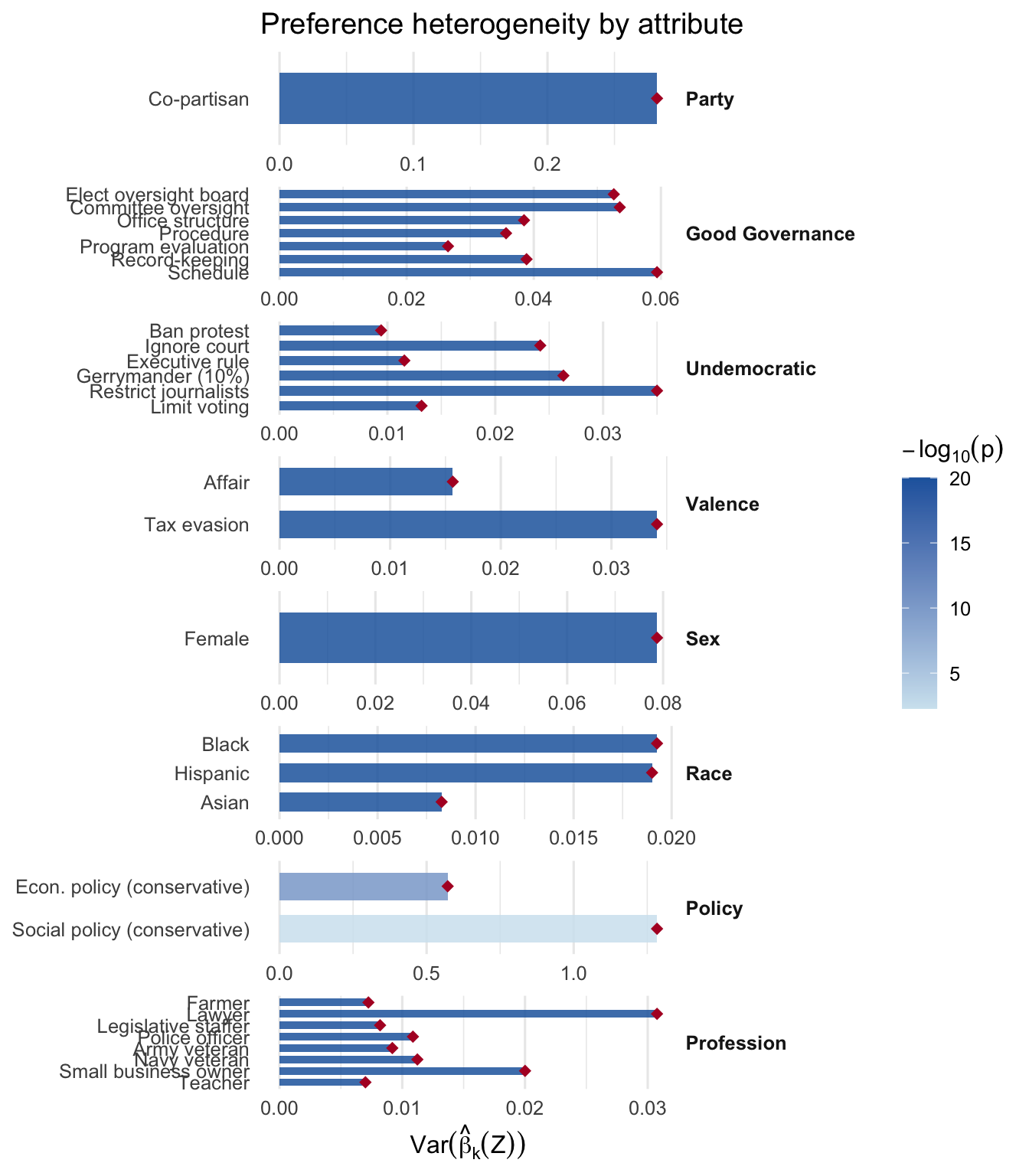
Decompose utility variance by attribute group. Party and policy should carry most of the weight; democracy attributes should account for a real but smaller share.
Does the per-attribute dispersion of \(\hat\beta_k(\mathbf Z_i)\) exceed what sampling noise alone would explain? A significant result for undem levels would confirm that the penalty for undemocratic behavior varies meaningfully across respondents.
plot_hetero(fit_gs, groups = gs_groups, labels = gs_labels)
Fewer than 5% of respondents have a positive coefficient on any undemocratic action — opposition to democratic backsliding is near-universal.
4.6.1 Fraction preferring
plot_fraction(fit_gs, groups = gs_groups, labels = gs_labels)
4.7 Direction and intensity
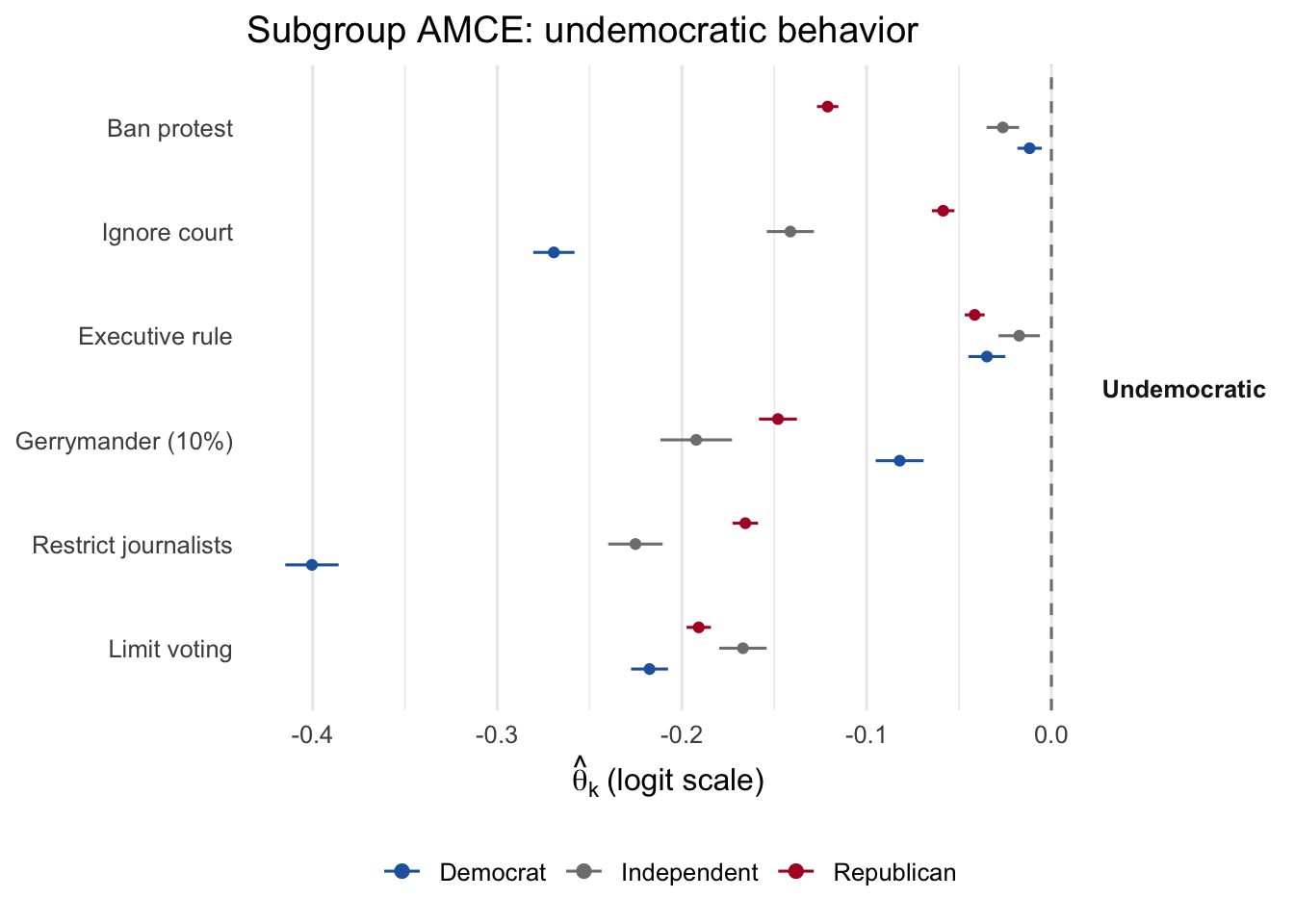
The undemocratic levels should show a large negative average direction (voters penalize them) coupled with high intensity. The structural question is whether the dispersion of those coefficients concentrates on co-partisans, as Graham and Svolik argue.
We re-average the held-out \(\hat\beta(\mathbf Z_i)\) separately for Democrats, Independents, and Republicans using sc_subgroup(). The resp_pid column on the standardized \(\mathbf Z\) matrix preserves the sign of the underlying -1/0/+1 encoding.
The structural model reveals that even strong partisans penalize undemocratic behavior, but the intensity of the penalty varies meaningfully with ideology.
4.9 Preference clustering
A complementary view on latent preference types: run k-means on the per-respondent \(\hat\beta(\mathbf Z_i)\) matrix to find clusters of respondents with similar preference profiles.
cl_gs <-sc_clusters(fit_gs, k =3L, seed =2024)cl_gs$estimate$sizes
4.10 Validating against the homogeneous-logit AMCE
The structural model nests the standard pooled-logit AMCE: under correct logit specification, \(\theta_k = \mathbb{E}[\beta_k(Z)]\) equals the homogeneous-logit coefficient on attribute \(k\). The new sc_validate_amce() export reports this comparison.
A correlation near \(r = 1\) across the 30 attribute levels confirms that nothing a reduced-form AMCE analysis would deliver is lost by using the structural model.