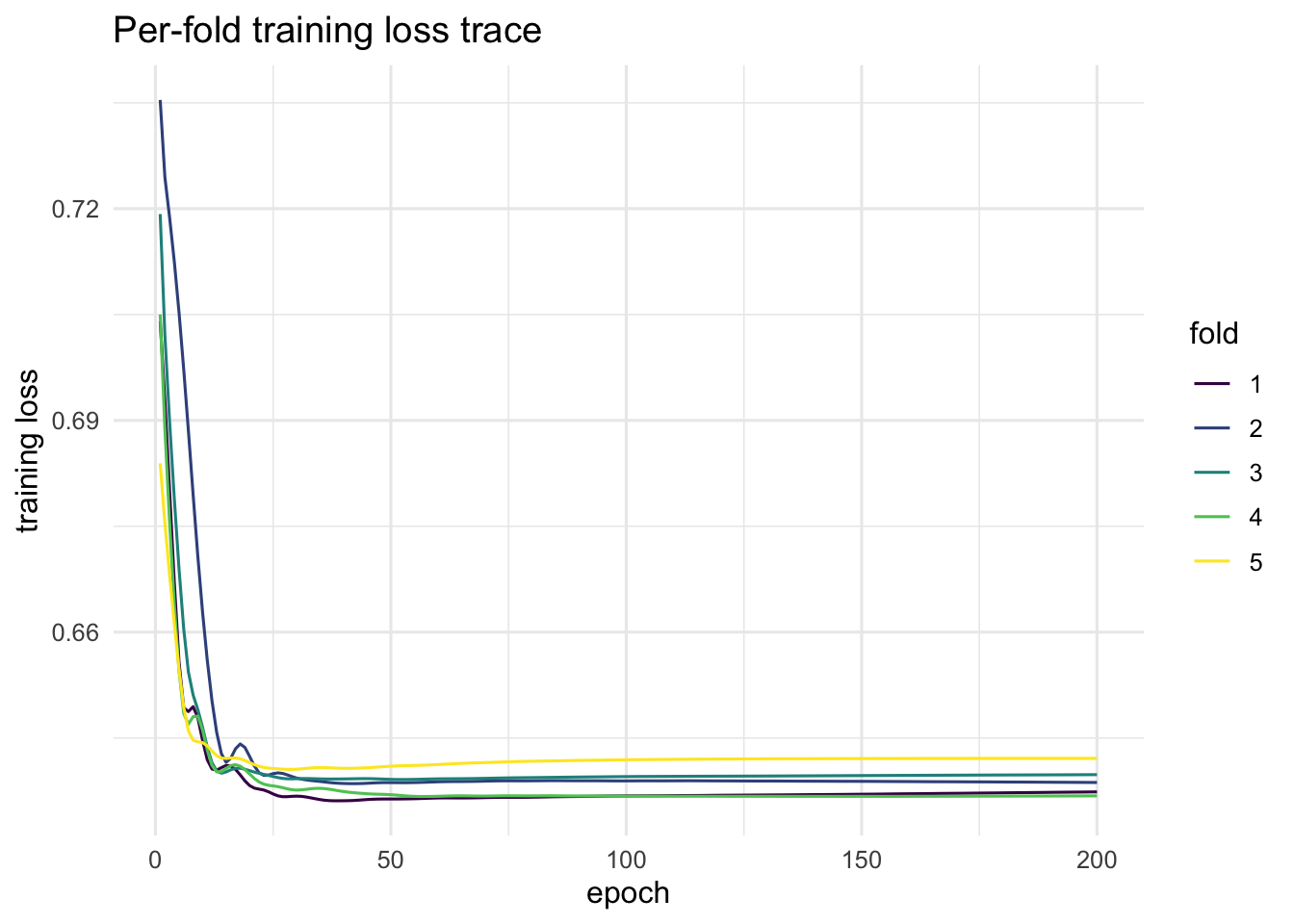
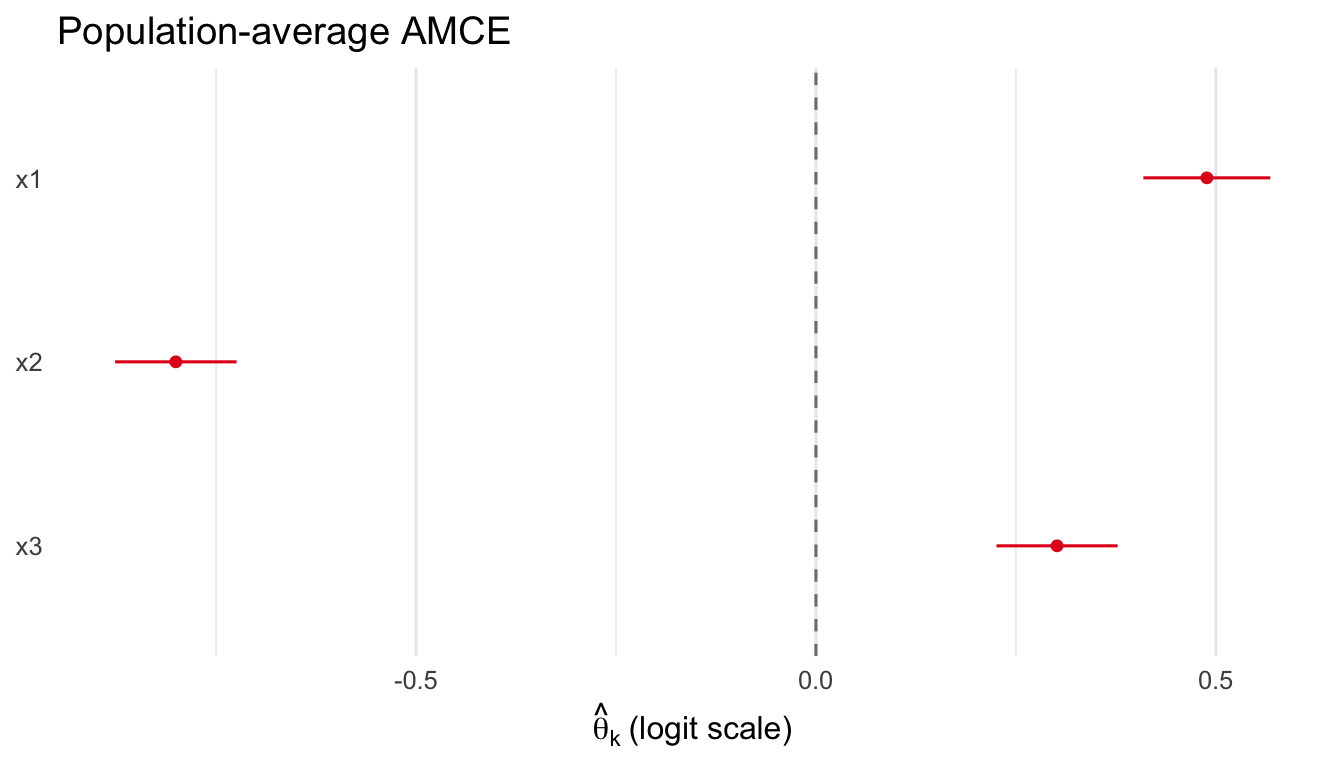
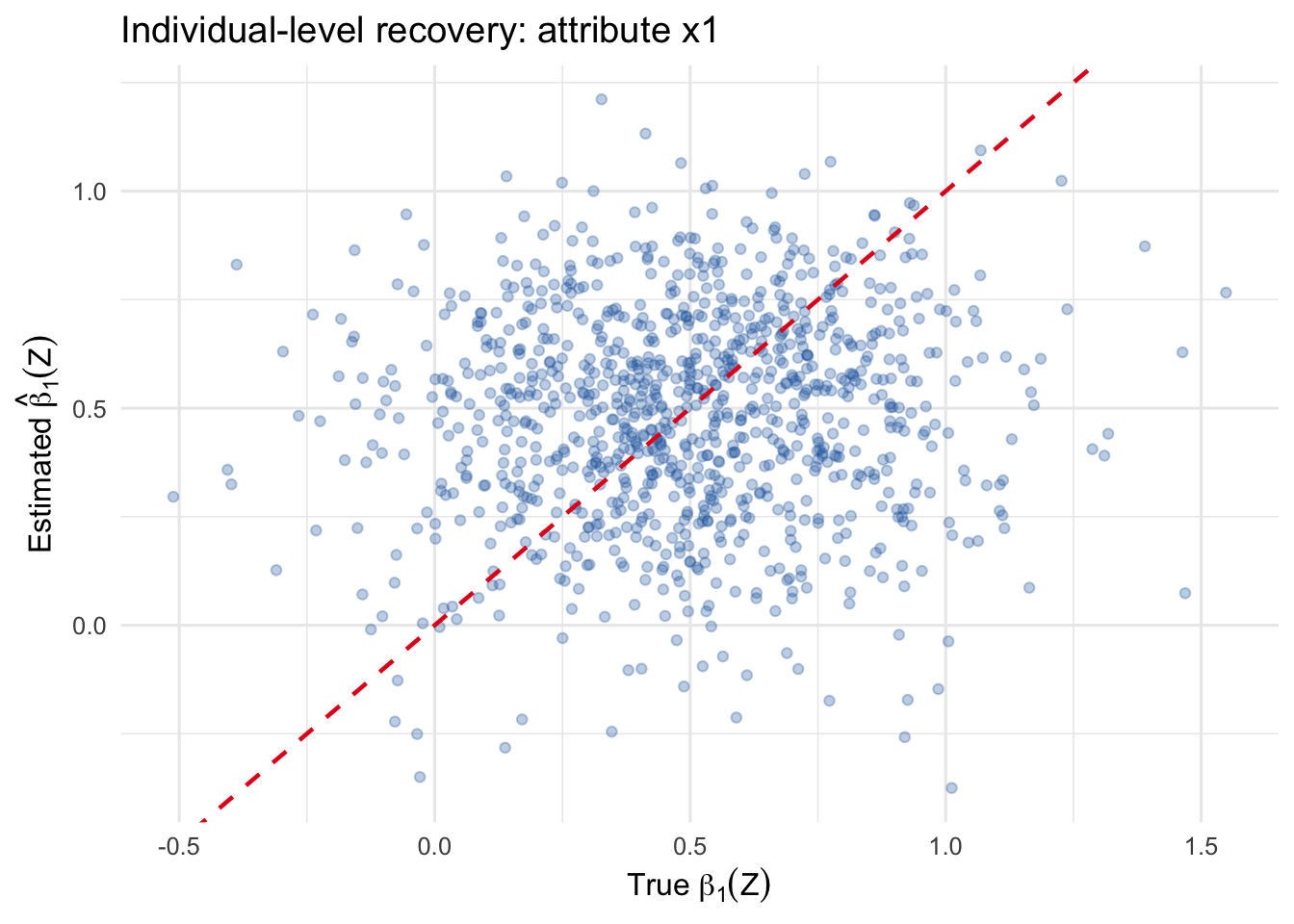
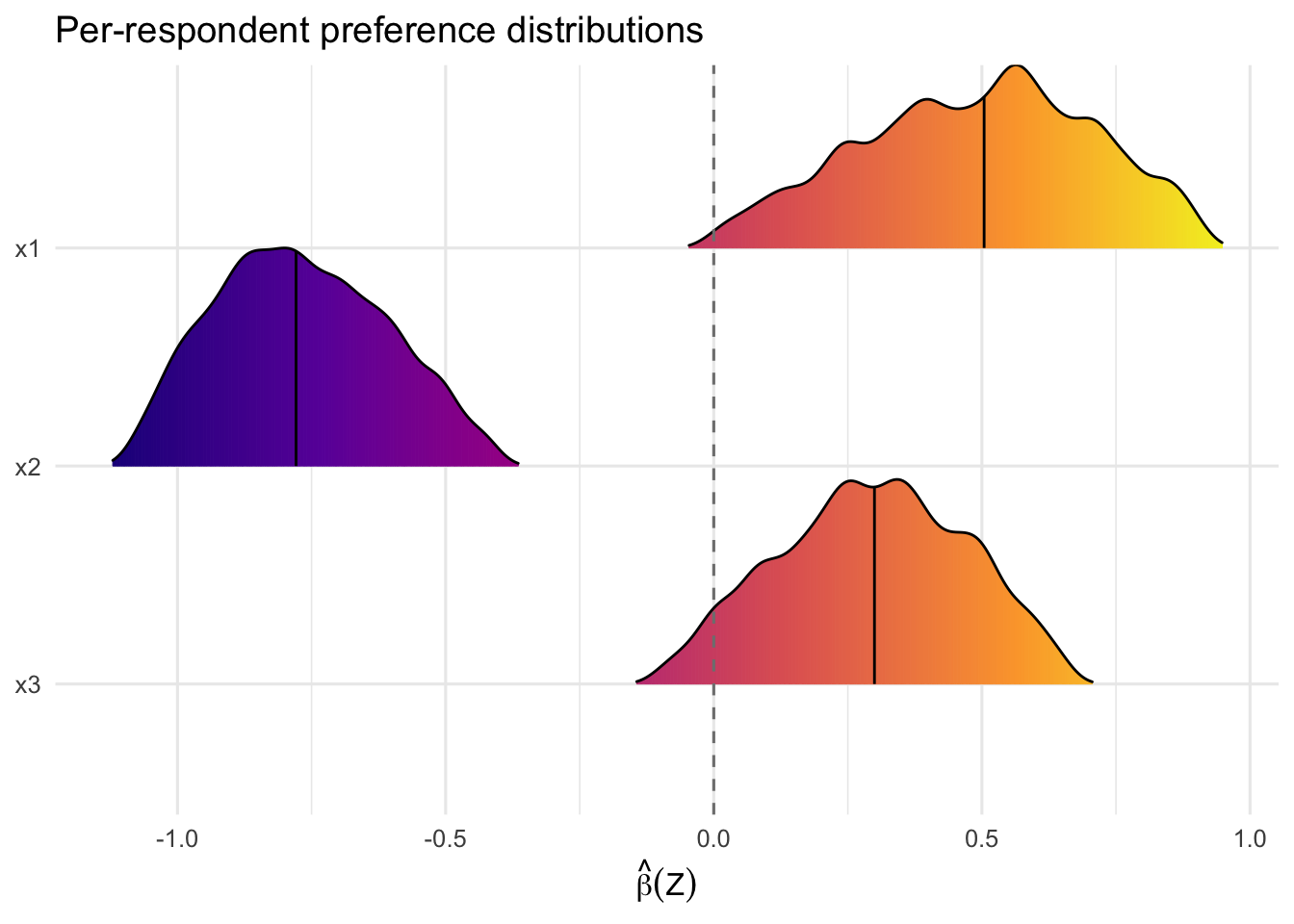
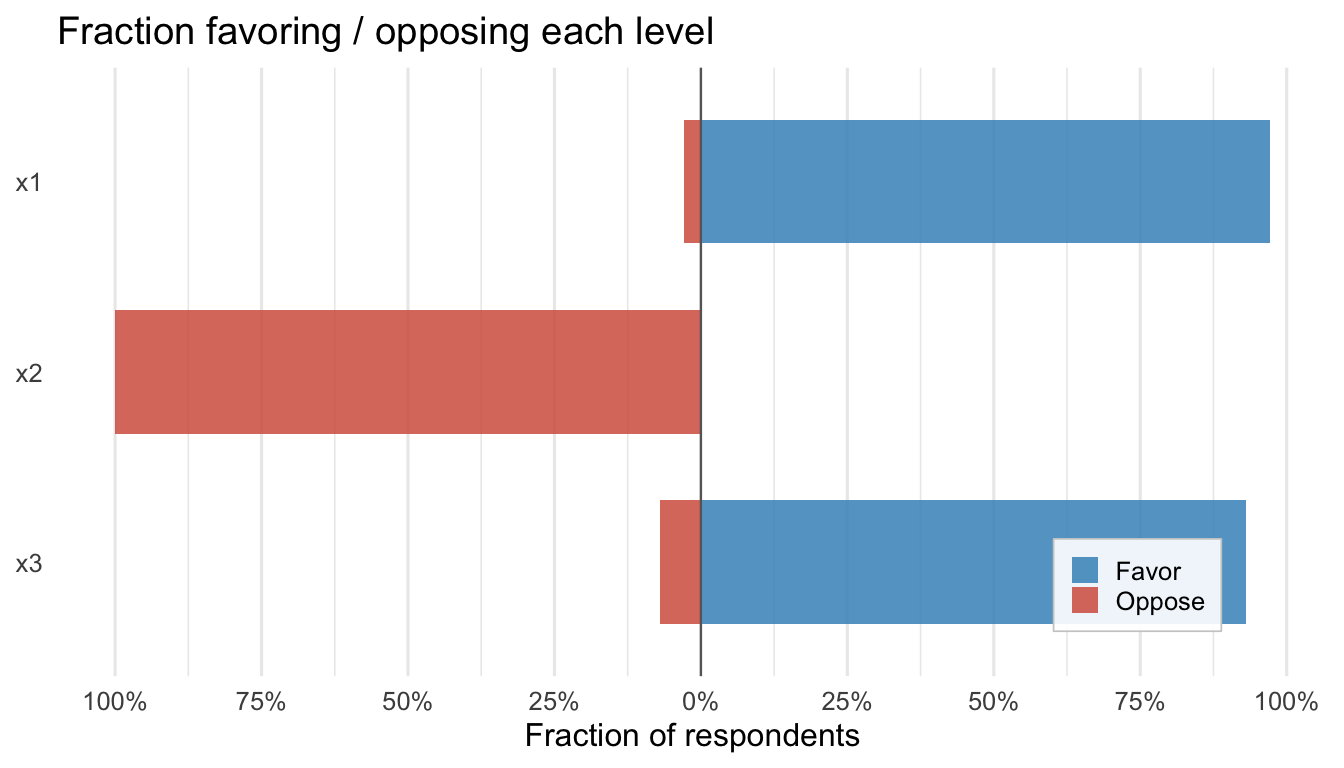
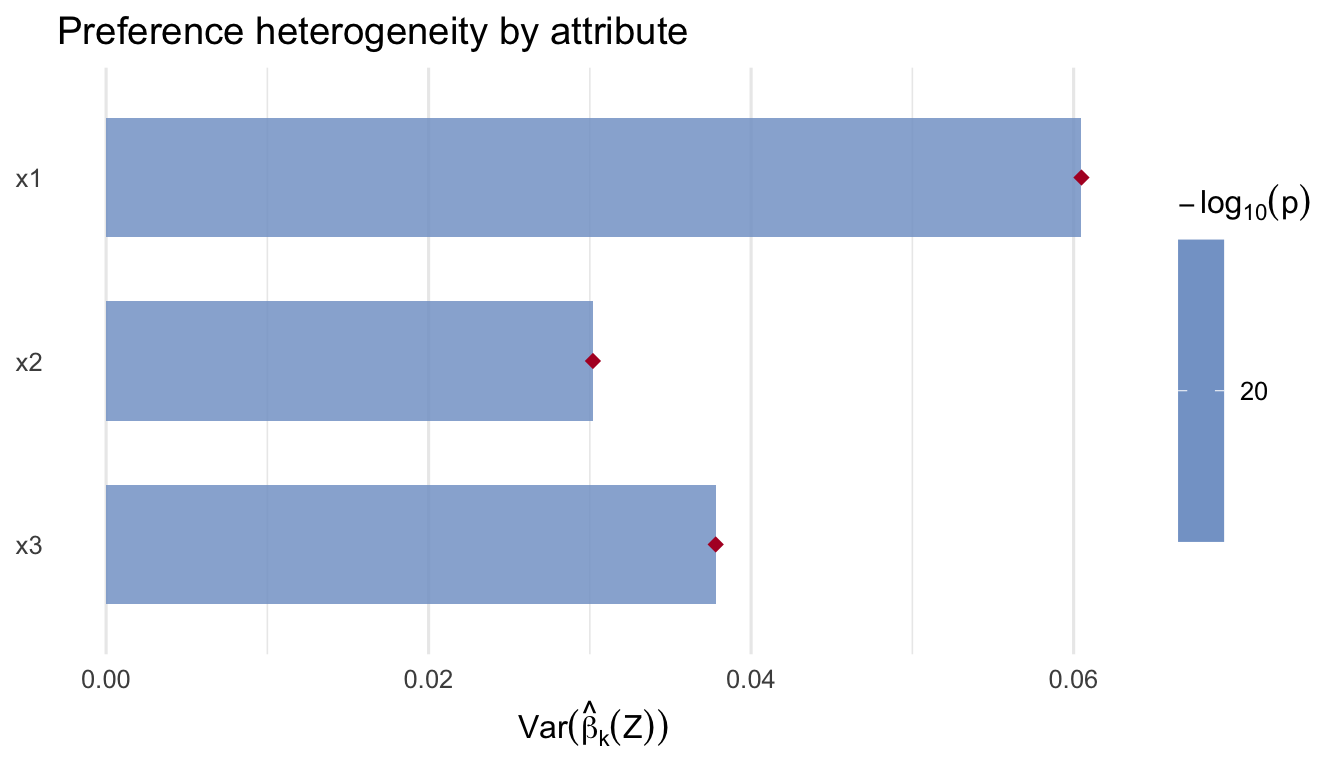
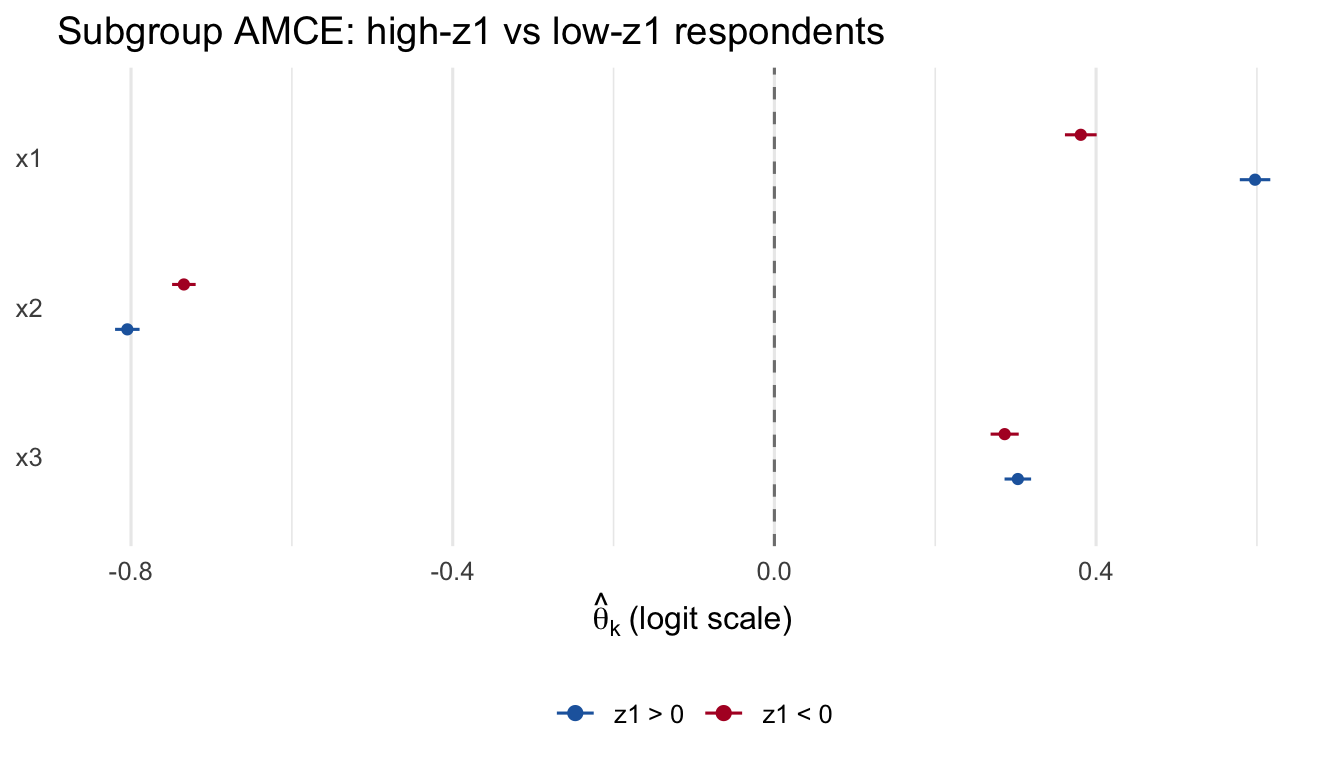
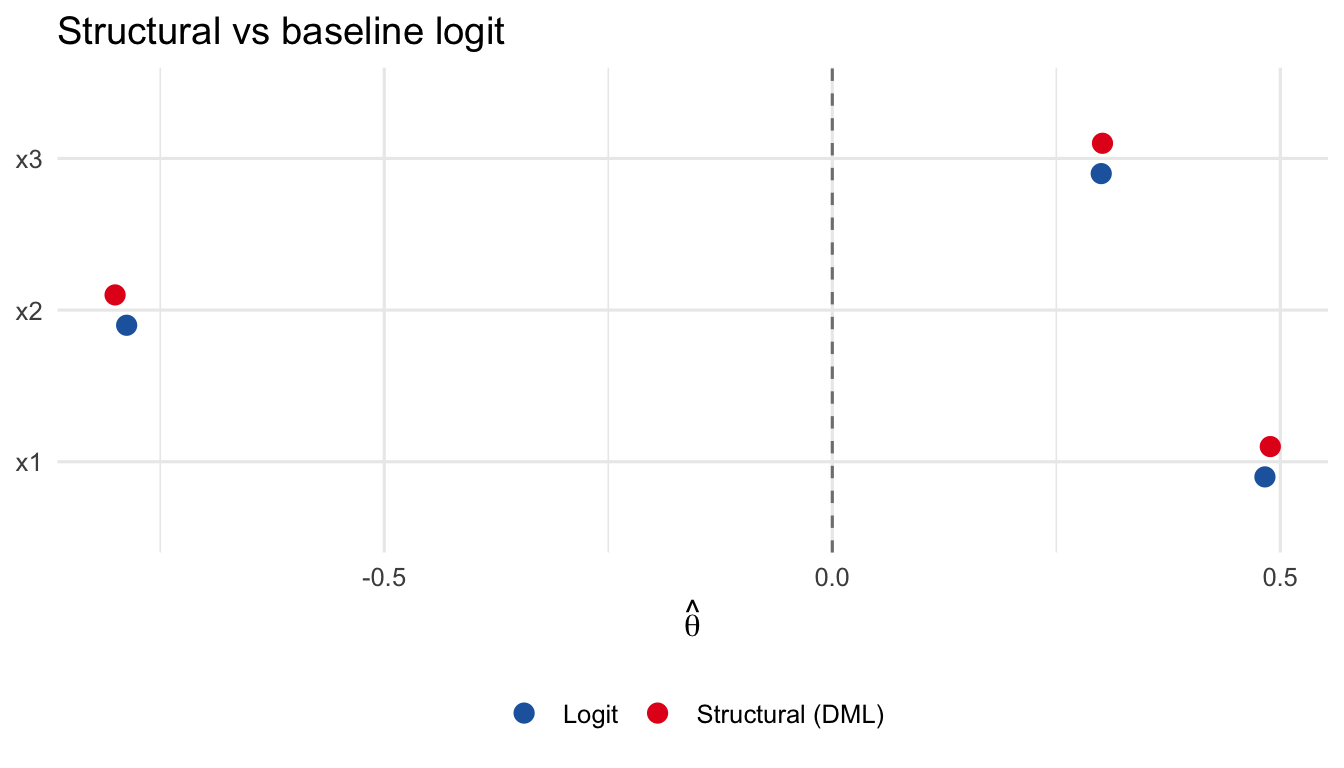
With these checks in hand, we proceed to real-data applications.
Abramson, Scott F., Korhan Koçak, and Asya Magazinnik. 2022. “What Do We Learn about Voter Preferences from Conjoint Experiments?” American Journal of Political Science 66 (4): 1008–20.
Acharya, Avidit, Jens Hainmueller, and Yiqing Xu. 2026. “Learning Preferences from Conjoint Data: A Hybrid Structural Deep Learning Approach.”
Athey, Susan, Julie Tibshirani, and Stefan Wager. 2019. “Generalized Random Forests.” Annals of Statistics 47 (2): 1148–78.
Ballard-Rosa, Cameron, Lucy Martin, and Kenneth Scheve. 2017. “The Structure of American Income Tax Policy Preferences.” Journal of Politics 79 (1): 1–16.
Bansak, Kirk, Jens Hainmueller, and Dominik Hangartner. 2016. “How Economic, Humanitarian, and Religious Concerns Shape European Attitudes Toward Asylum Seekers.” Science 354 (6309): 217–22.
———. 2023. “Europeans’ Support for Refugees of Varying Background Is Stable over Time.” Nature 620: 849–54.
Bansak, Kirk, Jens Hainmueller, Daniel J. Hopkins, and Teppei Yamamoto. 2023. “Using Conjoint Experiments to Analyze Election Outcomes: The Essential Role of the Average Marginal Component Effect.” Political Analysis 31 (4): 500–518.
Bechtel, Michael M., and Kenneth F. Scheve. 2013. “Mass Support for Global Climate Agreements Depends on Institutional Design.” Proceedings of the National Academy of Sciences 110 (34): 13763–68.
Berry, Steven, James Levinsohn, and Ariel Pakes. 1995. “Automobile Prices in Market Equilibrium.” Econometrica 63 (4): 841–90.
Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. “Double/Debiased Machine Learning for Treatment and Structural Parameters.” The Econometrics Journal 21 (1): C1–68.
Chernozhukov, Victor, Whitney K. Newey, and Rahul Singh. 2022. “Automatic Debiased Machine Learning of Causal and Structural Effects.” Econometrica 90 (3): 967–1027.
Chipman, Hugh A., Edward I. George, and Robert E. McCulloch. 2010. “BART: Bayesian Additive Regression Trees.” Annals of Applied Statistics 4 (1): 266–98.
Cuesta, Brandon de la, Naoki Egami, and Kosuke Imai. 2022. “Improving the External Validity of Conjoint Analysis: The Essential Role of Profile Distribution.” Political Analysis 30 (1): 19–45.
Egami, Naoki, and Kosuke Imai. 2019. “Causal Interaction in Factorial Experiments: Application to Conjoint Analysis.” Journal of the American Statistical Association 114 (526): 529–40.
Farrell, Max H., Tengyuan Liang, and Sanjog Misra. 2021. “Deep Neural Networks for Estimation and Inference.” Econometrica 89 (1): 181–213.
———. 2025. “Deep Learning for Individual Heterogeneity: An Automatic Inference Framework.”
Goplerud, Max, Kosuke Imai, and Nicole E. Pashley. 2025. “Estimating Heterogeneous Causal Effects of High-Dimensional Treatments: Application to Conjoint Analysis.” Annals of Applied Statistics 19 (2): 866–88.
Graham, Matthew H., and Milan W. Svolik. 2020. “Democracy in America? Partisanship, Polarization, and the Robustness of Support for Democracy in the United States.” American Political Science Review 114 (2): 392–409.
Green, Paul E., and V. Srinivasan. 1990. “Conjoint Analysis in Marketing: New Developments with Implications for Research and Practice.” Journal of Marketing 54 (4): 3–19.
Hainmueller, Jens, Daniel J. Hopkins, and Teppei Yamamoto. 2014. “Causal Inference in Conjoint Analysis: Understanding Multidimensional Choices via Stated Preference Experiments.” Political Analysis 22 (1): 1–30.
Ham, Dae Woong, Kosuke Imai, and Lucas Janson. 2024. “Using Machine Learning to Test Causal Hypotheses in Conjoint Analysis.” Political Analysis 32 (3): 329–44.
Hetzenecker, Stephan, and Maximilian Osterhaus. 2024. “Deep Learning for the Estimation of Heterogeneous Parameters in Discrete Choice Models.”
Kamakura, Wagner A., and Gary J. Russell. 1989. “A Probabilistic Choice Model for Market Segmentation and Elasticity Structure.” Journal of Marketing Research 26 (4): 379–90.
Leeper, Thomas J., Sara B. Hobolt, and James Tilley. 2020. “Measuring Subgroup Preferences in Conjoint Experiments.” Political Analysis 28 (2): 207–21.
McFadden, Daniel. 1974. “Conditional Logit Analysis of Qualitative Choice Behavior.” In Frontiers in Econometrics, edited by Paul Zarembka, 105–42. Academic Press.
———. 1981. “Econometric Models of Probabilistic Choice.” In Structural Analysis of Discrete Data with Econometric Applications, edited by Charles F. Manski and Daniel McFadden, 198–272. MIT Press.
McFadden, Daniel, and Kenneth Train. 2000. “Mixed MNL Models for Discrete Response.” Journal of Applied Econometrics 15 (5): 447–70.
Revelt, David, and Kenneth Train. 1998. “Mixed Logit with Repeated Choices: Households’ Choices of Appliance Efficiency Level.” Review of Economics and Statistics 80 (4): 647–57.
Rho, Sungmin, and Michael Tomz. 2017. “Why Don’t Trade Preferences Reflect Economic Self-Interest?” International Organization 71 (S1): S85–108.
Robinson, Thomas S., and Raymond Duch. 2024. “How to Detect Heterogeneity in Conjoint Experiments.” Journal of Politics 86 (2): 412–27.
Saha, Sparsha, and Ana Catalano Weeks. 2022. “Ambitious Women: Gender and Voter Perceptions of Candidate Ambition.” Political Behavior 44: 779–805.
Train, Kenneth E. 2009. Discrete Choice Methods with Simulation. 2nd ed. Cambridge University Press.
Zhirkov, Kirill. 2022. “Estimating and Using Individual Marginal Component Effects from Conjoint Experiments.” Political Analysis 30 (2): 236–49.